typedefint ElemType; //ElemType的类型根据实际情况而定,这里假定为int //顺序表数据结构 typedefstruct{ ElemType *elem; int length; }SqList;
Status InitList(SqList &L){ //构造一个空的顺序表L L.elem = new ElemType[MAXSIZE]; //为顺序表分配空间, if(!L.elem) exit(OVERFLOW); L.length = 0; return OK; }
// Function to print the elements of SqList voidOutPut(SqList L){ printf("Length: %d, Elements: ", L.length); for (int i = 0; i < L.length; i++) { printf("%d ", L.elem[i]); } printf("\n"); }
// Function to print the elements of SqList voidOutPut(SqList L){ printf("Length: %d, Elements: ", L.length); for (int i = 0; i < L.length; i++) { printf("%d ", L.elem[i]); } printf("\n"); }
//构造一个空的顺序表L Status InitList(SqList &L){ L.elem = new ElemType[MAXSIZE]; //为顺序表分配空间, if(!L.elem) exit(OVERFLOW); L.length = 0; return OK; }
Status InitList(LinkList &L){ L = new LNode; //或者用c语法:L = (LinkList)malloc(sizeof(LNode));(LinkList)是强制类型转换 L -> next = NULL; //头结点的指针域置空,指针域就是这个指针所指的结点的next域 //指针变量怎么操作它所指的结点的next的域呢,指针变量要操作某个成员,用-> return OK; }
Status DestoryList(LinkList &L){ //销毁单链表L LNode *p; //或者LinkList p while(L){ p = L; //从头结点开始 L = L -> next; //让一个指针指向下一个结点,L -> next的值就是下一个结点的地址 delete p; //c++:L = new LNode,delete p //c:L = (LinkList)malloc(sizeof(LNode)),free(p)
} return OK; }
[补充算法3]
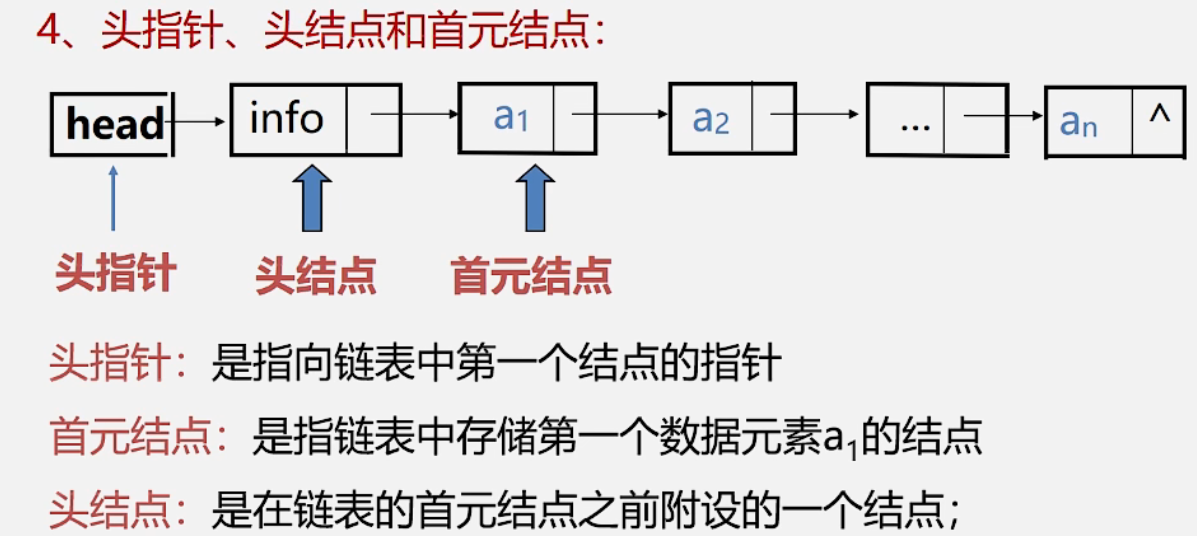
清空链表:链表仍然存在,但链表中无元素,成为空链表(头结点和头指针仍然存在)
[算法思路]
依次释放所有结点,并将头结点指针域设置为空
1 2 3 4 5 6 7 8 9 10 11 12
Status ClearList(LinkList &L){ //将L重置为空表 LNode *p,*q; //或者LinkList p,q; p = L ->next; //p指向第一个结点 while(p){ q = p -> next; delete p; p = q;
} L -> next = NULL; return OK; }
[补充算法4]
求单链表的表长
[算法思路]
从 首元结点开始,依次计数所有结点
1 2 3 4 5 6 7 8 9 10 11
intListLength(LinkList L){ //返回L中数据元素的个数 //会对表的内容改变用&L,不改变就用L Lnode *p; //或者LinkList p p = L -> next; //p指向第一个结点 int i = 0; while(p){ i ++; p = p -> next; } return i; }
//在线性表L中查找值为e的数据元素的位置序号 intLocateElem(LinkList L, Elemtype e){ LinkList p = L->next; int j = 1; while (p && p->data != e) { p = p->next; j++; } if (p) return j; elsereturn0; }
2.7.5 单链表的插入
单链表的插入步骤
互换后:我指向我自己,ai的地址会丢失
想互换,可以多加一个指针
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
//初试条件:L存在 //操作结果:在L中第i个位置之前插入新的数据元素e,L的长度加1 Status ListInsert(LinkList &L,int i,ElemType e){ int j = 0; LNode *p,*s; p=L; while (p && j< i-1){ //寻找第i-1个结点 p = p -> next; j++; } if(!p || j > i-1) return ERROR; s = new LNode; s -> data = e; s->next = p->next; p->next=s; return OK;
}
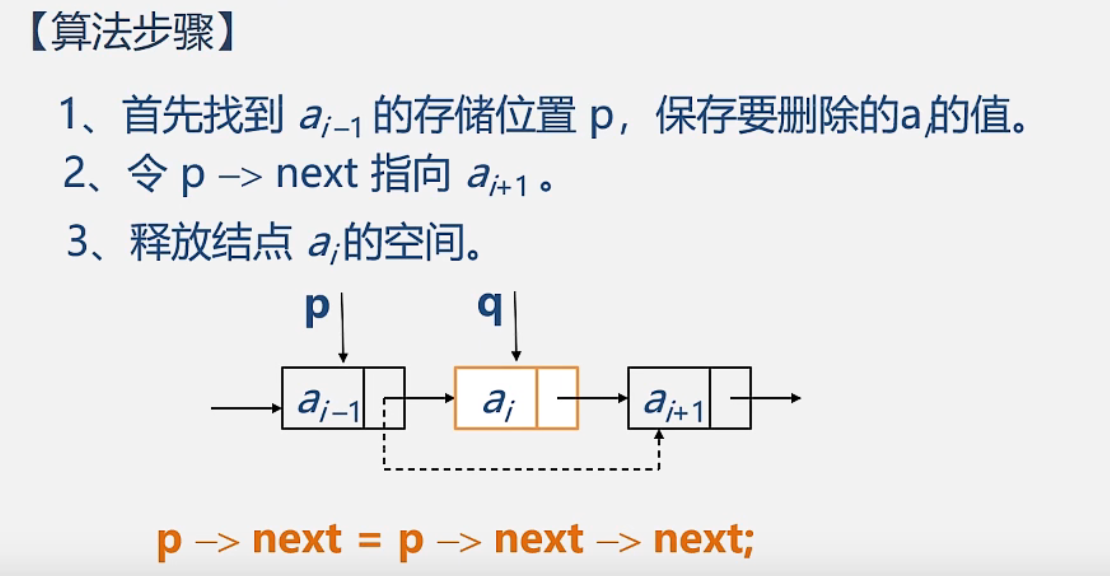
2.7.6 单链表的删除
删除第i个结点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
//初始条件:L存在 //操作结果:删除L的第i个数据元素,并用e返回其值,L的长度减1 Status ListDelete(LinkList &L, int i, ElemType &e){ int j; LNode *p,*q; p = L; j = 0; whlie(p->next && j<i-1){ //遍历寻找第i-1个元素 p = p->next; ++j; } if(!(p->next) || j>i-1) return ERROR; //第i个元素不存在 q = p->next; //临时保存被删结点的地址以备释放 p->next = q->next; //q的后继赋值给p的后继 e = q->data; //将q结点中的数据给e delete q; return OK; }
2.7.7 单链表的建立
头插法(前插法)
——元素插入在链表头部
头插法头插法建立单链表
1 2 3 4 5 6 7 8 9 10 11 12
//头插法创建单链表 voidCreateList_L(LinkList &L, int n){ L = new LNode; L -> next = NULL; //先建立一个带头结点的单链表 for(i = n; i>0; --i){ p = new LNode;//生成新结点,c语言是:p = (LNode*)malloc(sizeof(LNode)) scanf(&p->data);// c++是 cin>>p->data; p->next = L->next; //插入到表头 L->next = p; } }
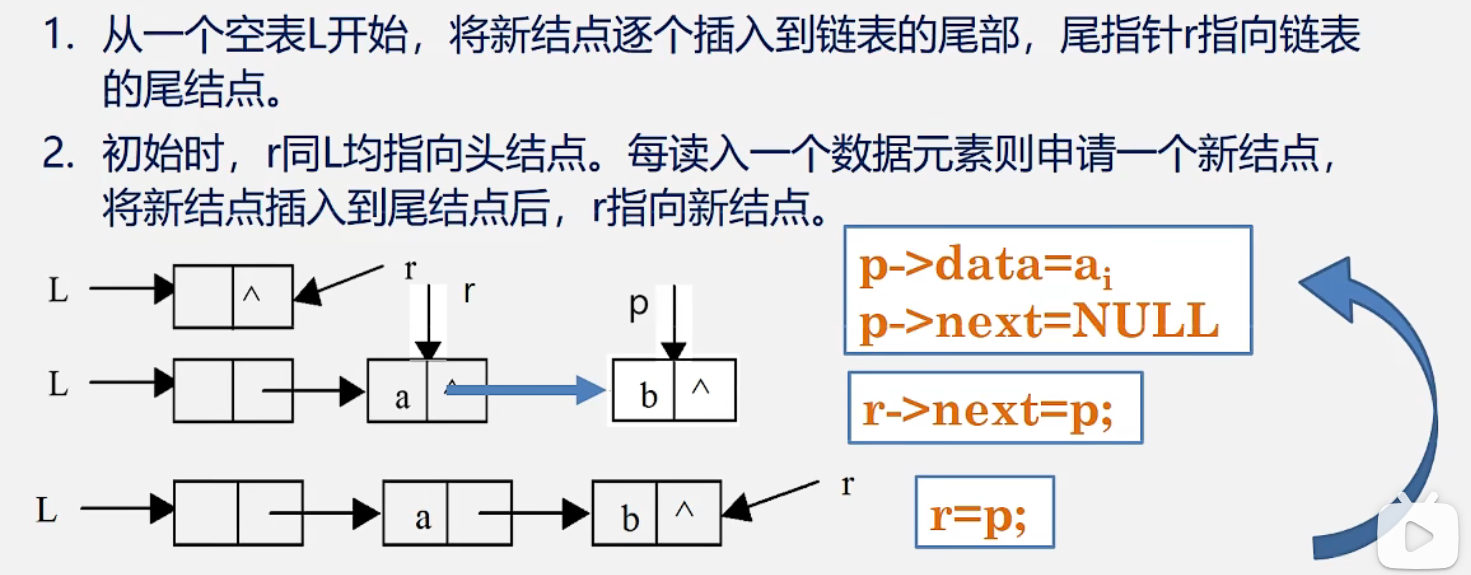
尾插法(后插法)
尾插法建立单链表
1 2 3 4 5 6 7 8 9 10 11 12 13 14
//正位序输入n个元素的值,尾插法创建单链表 voidCreateList_R(LinkList &L, int n){ L = new LNode; L -> next = NULL; //先建立一个带头结点的单链表 LNode *r; r = L; //尾指针r指向头结点 for(i = n; i>0; --i){ p = new LNode;//生成新结点,c语言是:p = (LNode*)malloc(sizeof(LNode)) scanf(&p->data);// c++是 cin>>p->data; p -> next = NULL; r -> next = p; //插入到表尾 r = p; //r指向新的尾结点 } }
⭐单链表小结
下面是在Vscode上写的代码,实现了上面所述的单链表的所有功能
注意销毁单链表的操作,笨🐭这里把它注释掉了,不然还要改,想测试的话可以ctrl
+ /
还要注意在讨论链表的状态时,"链表为空" 和 "链表不存在"
是两种不同的情况:
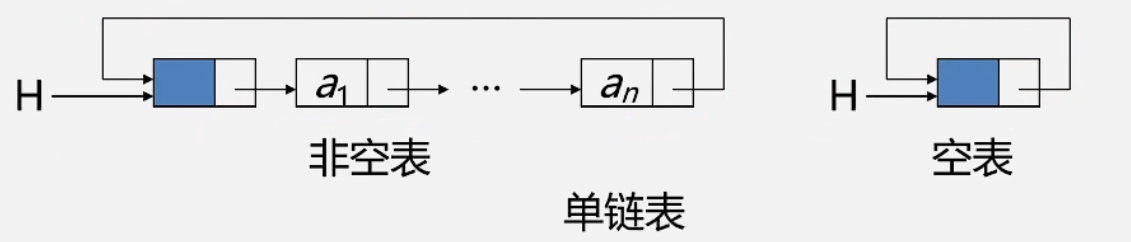
链表为空(Linked List is Empty):
这指的是链表被创建了,但没有添加任何元素,或者之前的元素都被删除了。在这种情况下,链表的头结点存在,但头结点的
next 指针为空,没有其他有效的结点。
链表不存在(Linked List does not exist):
这指的是链表根本没有被创建。在这种情况下,头结点都没有被分配内存,链表没有被初始化。
if (p->next == NULL) { printf("链表为空\n"); return; }
p = p->next; while (p) { printf("%d ", p->data); p = p->next; } printf("\n"); }
//初始化 Status InitList(LinkList &L){ L = new LNode; //或者用c语法:L = (LinkList)malloc(sizeof(LNode));(LinkList)是强制类型转换 L -> next = NULL; //头结点的指针域置空,指针域就是这个指针所指的结点的next域 //指针变量怎么操作它所指的结点的next的域呢,指针变量要操作某个成员,用-> return OK; }
//头插法创建单链表 voidCreateList_L(LinkList &L, int n){ L = new LNode; L -> next = NULL; //先建立一个带头结点的单链表 LNode *p; for(int i = n; i>0; --i){ p = new LNode; //生成新结点,c语言是:p = (LNode*)malloc(sizeof(LNode)) scanf("%d",&p->data); // c++是 cin>>p->data; p->next = L->next; //插入到表头 L->next = p; } }
//尾插法创建单链表 voidCreateList_R(LinkList &L, int n){ L = new LNode; L -> next = NULL; //先建立一个带头结点的单链表 LNode *r,*p; r = L; //尾指针r指向头结点 for(int i = n; i>0; --i){ p = new LNode;//生成新结点,c语言是:p = (LNode*)malloc(sizeof(LNode)) scanf("%d",&p->data);// c++是 cin>>p->data; p -> next = NULL; r -> next = p; //插入到表尾 r = p; //r指向新的尾结点 } }
//销毁单链表 Status DestoryList(LinkList &L){ //销毁单链表L LNode *p; //或者LinkList p while(L){ p = L; //从头结点开始 L = L -> next; //让一个指针指向下一个结点,L -> next的值就是下一个结点的地址 delete p; //c++:L = new LNode,delete p //c:L = (LinkList)malloc(sizeof(LNode)),free(p)
} return OK; }
//清空单链表 Status ClearList(LinkList &L){ //将L重置为空表 LNode *p,*q; //或者LinkList p,q; p = L ->next; //p指向第一个结点 while(p){ q = p -> next; delete p; p = q;
} L -> next = NULL; return OK; }
//求链表的表长 intListLength(LinkList L){ //返回L中数据元素的个数 //会对表的内容改变用&L,不改变就用L LNode *p; //或者LinkList p p = L -> next; //p指向第一个结点 int i = 0; while(p){ i ++; p = p -> next; } return i; }
//获取单链表某一位置上的元素 Status GetElem(LinkList L,int i,ElemType &e){ int j; LNode *p; p = L->next; //让p指向链表L的第一个结点 j = 1; //j为计数器 while(p && j<i){ //向后扫描,直到p指向第i个元素或p为空 p = p->next; ++j; } if(!p || j>i) return ERROR; //第i个元素不存在 e = p -> data; //第i个元素的数据 return OK;
}
//单链表的按值查找 intLocateElem(LinkList L, int e){ LinkList p = L->next; int j = 1; while (p && p->data != e) { p = p->next; j++; } if (p) return j; elsereturn-1; }
//单链表的插入 Status ListInsert(LinkList &L,int i,ElemType e){ int j = 0; LNode *p,*s; p=L; while (p && j< i-1){ //寻找第i-1个结点 p = p -> next; j++; } if(!p || j > i-1) return ERROR; s = new LNode; s -> data = e; s->next = p->next; p->next=s; return OK;
}
//单链表的删除 Status ListDelete(LinkList &L, int i, ElemType &e){ int j; LNode *p,*q; p = L; j = 0; while(p->next && j<i-1){ //遍历寻找第i-1个元素 p = p->next; ++j; } if(!(p->next) || j>i-1) return ERROR; //第i个元素不存在 q = p->next; //临时保存被删结点的地址以备释放 p->next = q->next; //q的后继赋值给p的后继 e = q->data; //将q结点中的数据给e delete q; return OK; }
intmain(){ int empty; int length; int m; //存储从单链表中获取的某一位置上的元素 int n; //存储某一元素在单链表中的位置 int a; //删除操作中删除的那个元素的值
//或者void ListInsert_DuL(DuLinkList &L,int i,ElemType e){} Status ListInsert_DuL(DuLinkList &L,int i,ElemType e){ //在带头结点的双向链表中第i个位置之前插入元素 e if(!(p=GetElem_DuL(L,i))) return ERROR; //在L中确定第 i个元素的位置指针 p,p为 NULL时,第i个元素不存在 s = new DuLNode; //生成新结点*s s->data=e; //将结点*s 数据域置为 e s->prior = p->prior; //将结点*s 插人L中,对应上图中① p->prior->next = s; //对应上图中② s->next = p; //对应上图中③ p->prior = s; //对应上图中④
return OK; }
2.9.4 双向链表的删除
假设要删除双向链表的结点 ptr,只需要把 ptr
结点的前驱和后继安排明白即可。
双向链表的删除
1 2 3 4 5 6 7 8 9
voidListDelete_DuL(DuLink &L, int i, ElemType &e){ // 删除带头结点的双向循环链表 L 的第 i个元素,并用 e 返回 if(!(p=GetElem_DuL(L,i))) return ERROR; e = p -> data; p -> prior -> next = p -> next; p -> next -> prior = p -> prior; free(p); return OK; }